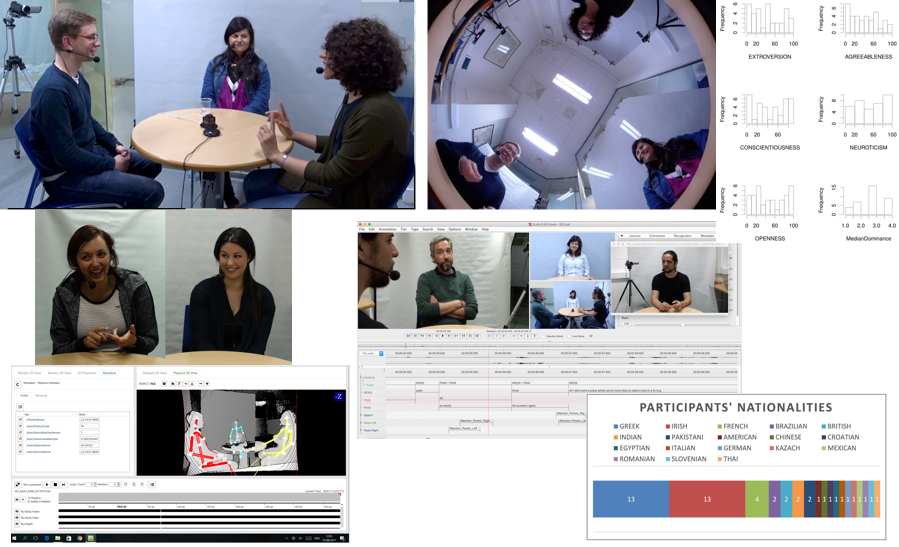
MULTISIMO has developed a multimodal corpus within the project and targets the investigation and modeling of collaborative aspects of multimodal behavior in groups that perform simple tasks.
The core of the MULTISIMO corpus is a data collection of recorded interactions between groups of three people. In each interactive session two participants collaborate with each other to solve a quiz while assisted by a human facilitator. The audiovisual files are annotated with information about full speech transcription, dialogue structure, feedback of the facilitator, laughter type annotation, and partial gesture annotation. In addition, the corpus includes data analysis, survey materials, i.e. personality tests and experience assessment questionnaires filled in by all participants and participant profiling data.
The design and implementation of the MULTISIMO corpus has been approved by the SCSS research ethics committee and the Data Protection Officer of Trinity College Dublin. The research complies with the EU General Data Protection Regulation (GDPR) regarding the data privacy management. Following the consent given by participants during the recording process, a large part of the dataset (18 out of the 23 recorded interactions) corresponding to approximately 3 hours, is shared under a non-commercial licence.
Content
Information about the corpus structure and content can be found in the readme file.Licence
Access to and any use of the Multisimo corpus dataset is bound by a non-commercial Licence. Licensed Rights are granted in consideration of acceptance of these terms and conditions, and the Licensor grants such rights in consideration of benefits the Licensor receives from making the Licensed Material available under these terms and conditions.Citation
For any publication related to this corpus, please cite the following paper:
Koutsombogera, Maria and Vogel, Carl (2018).
Modeling Collaborative Multimodal Behavior in Group Dialogues: The MULTISIMO Corpus.
In Proceedings of the 11th Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan,
pp. 2945-2951. [bib]
Download the Corpus
To download the corpus, please read the accompanying Licence and accept its terms in the form below, together with accurately filling out the rest of the information requested. Once submitted, you will receive further downloading instructions at the e-mail address you have provided.